Fly series: Dealing with DbConnection errors
by Paulo Gonzalez
2025-02-13 | sql postgres dbeaver
EDIT 1: I recently had to do this again and the `destroy` command applied on a primary didn't automatically promote one of the replicas. The solution was to `ssh` into the one of the db apps (all replicas, no primary) and manually promote a replica to primary using `repmgr`. I have notes and will write them down when I have a little bit of time later. I'm unsure of why this failed at the moment, but the current hypotheses are:
- Successful failure -> I have always run one of the commands below WITHOUT `--force` first, getting an "error" and then using `--force` after. The first "error" triggers the failover and by the time I run the second command, things work, helping me fail successfully.
- Regression -> A regression in the cli brought back this bug. Someone else experienced this error a couple years ago and the solution was to update their cli to a version that didn't have that bug.
For now, I suggest doing a failover manually for the below to work as you'd expect, before destroying the machine.
EDIT 2: Seems like it was not just me:
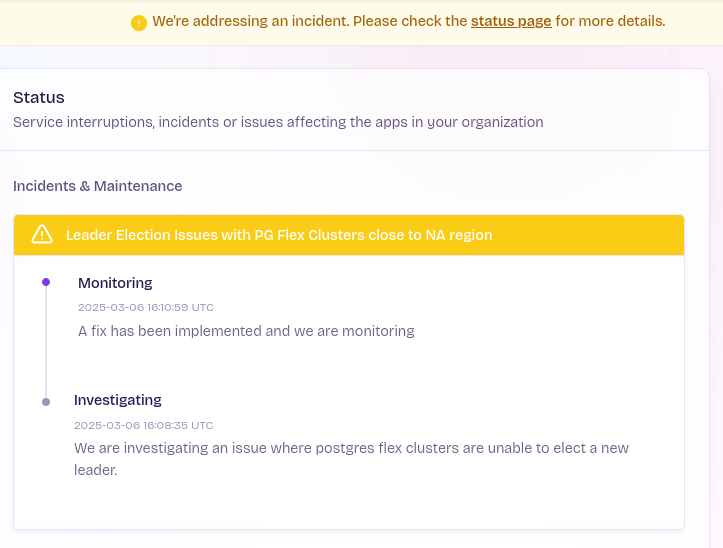
Sometimes, things break. That's just how things are. One time, I realized I was getting DbConnection errors in an app hosted on Fly (using Fly Posgres), even with low usage in an app. It was odd, came out of nowhere. You could see the connections dropping and then going back up.
The confusing thing was that there was no trigger for this. It just started happening. After some research, I decided to contact Fly's support, which have always been super helpful. They showed me that one of the three machines I had for my database was stuck in a boot loop and would never reach available state. It seemed like it was just long enough to take some connections from the pool, but would crash soon later. It was there on the dashboard if you looked at all the machines. It was tucked a click away though, I was not able to see it from the main dashboard, the db (overall health) was green. Now I know to look there and in hindsight, I should have.
Support gave me direction on how to fix the problem. In short, you had to destroy the bad machine and clone a good one. That's why we have more than 1 machine (like Fly suggests). As usual, I write a lot when working and had some notes. When this happened again a couple weeks back, I was prepared. Here are the notes that have helped me:
# Steps to destroy a bad machine (and volume) and clone a good one - fly postgres
# list the machines, get the id for the bad one
$ fly machine list --app YOUR_DB_APP
# list the volumes, get the volume attached to the bad one
$ fly volumes list --app YOUR_DB_APP
$ fly machine destroy BAD_MACHINE_ID --app YOUR_DB_APP
# had to use --force, cli suggested, worked
$ fly machine destroy BAD_MACHINE_ID --force --app YOUR_DB_APP
$ fly volumes destroy BAD_VOLUME_ID --app YOUR_DB_APP
$ fly volumes list --app YOUR_DB_APP
$ fly machine clone GOOD_MACHINE_ID --region TARGET_REGION --app YOUR_DB_APP
# confirm
$ fly machine list --app YOUR_DB_APP
$ fly volumes list --app YOUR_DB_APP
Hope this helps! It has helped me a couple of times already. I also want to give props to Fly's email support. It's always been helpful.